Índice.
Resumen…………………………………………………………………………1
Abstract………………………………………………………………………...1
Antecedentes……………………………………………………………………2,3
Definición del
problema…………………………………………………………4
Objetivo
general………………………………………………………………….5
Justificación……………………………………………………………………….6
Fundamento
teórico………………………………………………………………7
Materiales y
métodos……………………………………………………………..8
Resultados…………………………………………………………………………9,10,
Conclusiones……………………………………………………………………….11
Recomendaciones…………………………………………………………………12
Fuentes consultadas………………………………………………………………..13
Resumen.
Las cadenas de ADN pueden enrollarse una sobre otra
de dos formas: en sentido horario o en sentido anti horario. Es decir que si
las cadenas giran a favor del movimiento de las agujas del reloj diremos que lo
hacen en sentido horario, de lo contrario el sentido que adquiere el giro será
denominado anti horario. Las variaciones conformacionales del ADN, está
asociado principalmente por las variaciones en la conformación de los
nucleótidos que constituyen el ADN. Actualmente se reconoce que e. El ADN forma
estructuras poco usuales tales como cruciformes o disposiciones en cadena
triple y codos cuando interacciona con ciertas proteínas.
Abstract.
DNA
strands can be rolled over one another in two ways: clockwise or
counter-clockwise. That is, if the spin chains in favor of the motion of the
clock will say that they do clockwise, otherwise the meaning that the spin is
called anti clockwise. This determines that there are two variants of DNA,
which is wound clockwise is called Right Handed DNA and does so in a manner
contrary is called Left Handed Z-DNA or DNA conformational changes, is
associated mainly from changes in the conformation of the nucleotides that make
up DNA. It is now recognized that DNA structure is not a straight, steady,
monotonous and uniform. The DNA is unusual structures such as cruciform or
triple string arrangements and elbows as he interacts with certain proteins.
Antecedentes.
Hasta
casi la mitad del siglo XX una de las preguntas que mantenía ocupados a los
investigadores en el campo de la Biología Molecular y Celular era ¿Qué molécula
posee la información genética? La mirada apuntaba principalmente a dos macromoléculas:
las Proteínas y el ADN. Fue hasta la década delos 50´s que gracias a
las experiencias y trabajos de Alfred D. Hershey y su colega Martha Chase se
pudo comprobar, a través de estudios realizados con virus Bacterianos, que la
información genética era portada por la molécula de ADN.
El
broche de oro lo constituye el trabajo realizado por el Bioquímico
estadunidense James D. Watson y el bioquímico Británico Francis Crick. Haya por
el 25 de abril del año de 1953 la revista, Nature publica el modelo atómico
de la estructura del ADN. Mucho de este trabajo solo fue recopilación de datos
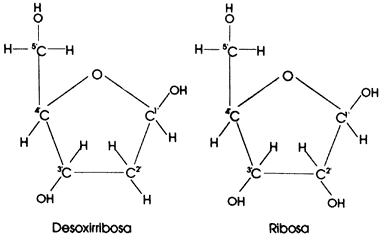
pues ya se sabía que: la molécula de ADN era muy grande, larga y delgada.
Compuesta por nucleótidos que contenían las bases nitrogenadas Adenina, Timina,
Citosina y Guanina. También Erwin Chargaff ya había analizado el ADN y confirmó
que las cantidades de las Bases Púricas eran iguales a las de las Bases
Pirimídicas. En síntesis, las cantidades de Adenina eran iguales a las de
Timina y, las de Citosina se correspondían a las de Guanina.
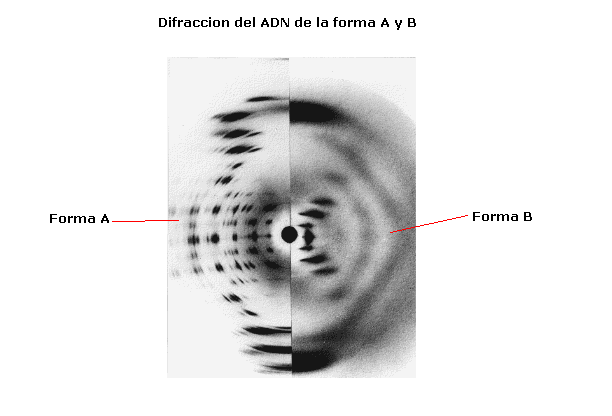
El otro tipo de datos eran los procedentes estudios
propuestos por; Maurice H. F. Wilkins y Rosalin Franklin sobre la difracción de
rayos X sobre fibras de ADN. Mediante esta técnica descubrieron que: Las bases
púricas y pirimidínicas se encuentran unas sobre otras, apiladas a lo largo del
eje del polinucleótido a una distancia de 3,4Å.
Las bases son estructuras planas orientadas de forma perpendicular al eje. El
diámetro del polinucleótido es de 20 Å y
está enrollado helicoidalmente alrededor de su eje. Cada 34 Å
se produce una vuelta completa de la hélice.
Con todos estos datos, Watson y Crick intentaron construir el modelo de
ADN. Para llevar la gran cantidad de información genética el modelo debía
considerar dos aspectos fundamentales: ser heterogéneo y variado. Armaron así
el modelo en hojalata y alambre y, como quien arma un rompecabezas, encajaron
cada pieza en su lugar.
A medida que armaban el modelo, se dieron cuenta que los nucleótidos que
conformaban la molécula de ADN podían encajarse en cualquier orden. Dado que la
molécula de ADN posee miles de nucleótidos de largo, la variabilidad y la
heterogeneidad estaban aseguradas, puesto que la combinación de las bases se
volvía incalculable. Otra de las conclusiones a las que arribaron fue que la
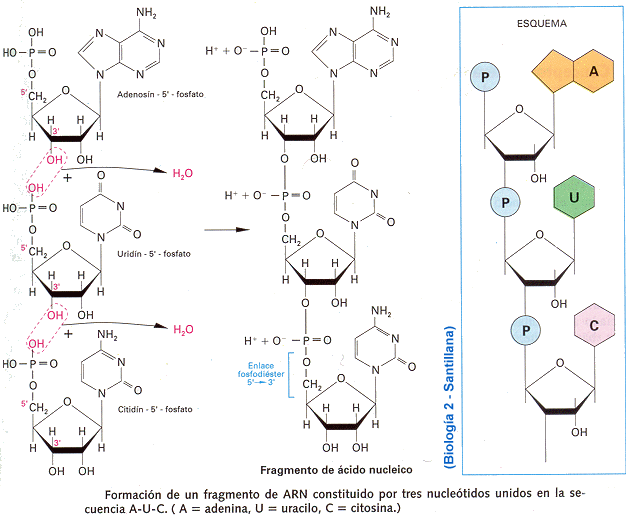
cadena poseía una dirección, ya que cada grupo fosfato está unido a un azúcar
en la posición 5´ (el quinto carbono en el anillo de azúcar) y al otro azúcar
en la posición 3´ (el tercer carbono en el anillo del azúcar). Así la cadena
tiene un extremo 5´ y otro 3´. Lo interesante del trabajo fue el armado de la
cadena complementaria. Las Adeninas únicamente podían aparearse con las Timinas
y las Guaninas con las Citosinas. Pero, para que esto ocurra, la dirección de
las cadenas debía ser inversa. Es así como extremo 5´ se aparea con el 3´, cabe
decir que ambas cadenas son Antiparalelas.
La doble hélice exige que cada una de las Bases Nitrogenadas de una
cadena se aparee en forma complementaria con la base de la otra cadena. Este apareamiento
tiene lugar mediante las uniones Puente de Hidrógeno que se forman entre las
mismas. Entre las Bases Adenina y Timina se forman dos uniones Puente de
Hidrógeno, mientras que entre la Guanina y la Citosina se establecen tres
uniones de la misma naturaleza. No esta demás aclarar que la unión entre las
Bases Citosina y Guanina será, en consecuencia, más fuerte que la que se
establece entre la Adenina y la Timina.
Definición del problema
ADN no es una estructura recta, estable, monótona
ni uniforme, por ello se pretende estudiar las diferentes formas que presenta
esta biomolécula, encargada de llevar a cavo el metabolismo celular, la
duplicación de el mismo y, además se encarga de guardar toda la información
genética.
Objetivo
general.
El objetivo Principal de este primer trabajo es que
el estudiante adquiera familiaridad con la biología molecular, que descubra que
además de la forma A, B y Z, existen muchas formas biológicas en las que
podemos encontrar el DNA y las implicancias de esto para la expresión y la
vida, también se busca que se usen los recursos web y las TIC´s.
Justificación.
Ya que el ADN no es una estructura recta, estable,
monótona y ni uniforme el presente trabajo se realizara con la finalidad de
estudiar y comprender las estructuras en las que se encuentra el ADN, ya que en
la mayor parte de la naturaleza esta biomolécula se encuentra en el mayor de
los casos en la forma B, que fue propuesta en el año de 1953.
Fundamento
teórico.
El
modelo de la Doble Hélice propuesto por Watson y Crick se basa en estudios del
ADN en disolución. La denominada forma B ó ADN-B tiene un mayor interés
biológico ya que es la que presenta el ADN en interacción con las proteínas
nucleares. Además de la forma B, existen otras estructuras posibles que puede
presentar el ADN.
ADN-B:
ADN en disolución, 92% de humedad relativa, se encuentra en soluciones
con baja fuerza iónica se corresponde con el modelo de la Doble Hélice.
ADN-A:
ADN con 75% de humedad, requiere Na, K o Cs como contraiones, presenta
11 pares de bases por giro completo y 23 Å de
diámetro. Es interesante por presentar una estructura parecida a la de los
híbridos ADN-ARN y a las regiones de autoapareamiento ARN-ARN.
ADN-Z: doble
hélice sinistrorsa (enrollamiento a izquierdas), 12 pares de bases por giro
completo, 18 de
diámetro, se observa en segmentos de ADN con secuencia alternante de bases púricas
y pirimidínicas, debido a la conformación alternante de los residuos
azúcar-fosfato sigue un curso en zig-zag. Las posiciones N7 y C8 de la Guanina
son más accesibles.
8
Materiales
y métodos.
Este trabajo se realizó en el centro de información
del instituto tecnológico de ciudad Altamirano. A través de consultas
bibliográficas y de internet.
Resultados.
ADN-C:
Se obtiene en presencia de iones Li, muestra 9+1/3 pares de bases por
giro completo y 19 de diámetro de cadena sencilla. Se sintetiza a partir de una
hebra simple de ARNm maduro. Se suele utilizar para la clonación de genes
propios de células eucariotas en células procariotas, debido a que, dada la
naturaleza de su síntesis, carece de intrones.
ADN triple hélice o ADN-H: Es
posible obtener tramos de triple hélice intercalando oligonucleótidos cortos
constituidos solamente por pirimidinas (timinas y citosinas) en el surco mayor
de una doble hélice. Este oligonucleótido se une a pares de bases A-T y G-C
mediante enlaces de hidrógeno tipo Hoogsteen que se establecen entre la T o la
C del oligonucleótido y los pares A-T y G-C de la doble hélice.
ADN con enrollamiento paranémico: Las
dos hélices se pueden separar por traslación, cada hélice tiene segmentos
alternantes dextrorsos y sinistrorsos de unas cinco bases. Uno de los
principales problemas del modelo de la doble hélice es el enrollamiento
plectonémico, para separar las dos hélices es necesario girarlas como un
sacacorchos.
ADN nódulo: consiste en dos pares de
triples hélices intermoleculares
ADN cuádruplex: "In
vitro" se han obtenido cuartetos de Guanina (ADN cuádruplex) unidas
mediante enlaces tipo Hoogsteen, empleando polinucleótidos que solamente
contienen Guanina (G). Los extremos de los cromosomas eucarióticos (telómeros)
tienen una estructura especial con un extremo 3' OH de cadena sencilla
(monocatenario) en el que se repite muchas veces en tándem una secuencia rica
en Guaninas. Se piensa que el ADN cuádruplex telomérico serviría para proteger
los extremos cromosómicos de la degradación enzimática.
ADN dislocado: Esta estructura
se forma mediante el desenrroscamiento de la doble hélice y el posterior
apareamiento de una copia de la repetición directa con la copia adyacente en la
otra cadena.
Conclusiones.
Ya sea de manera natural o artificial existen diferentes
formas de ADN que esta dado por factores como el porcentaje de hidratación y
concentración salina. Pero ya sea cualquier forma todas las cadenas son
antiparalelas, ademas ciertas formas son mas largas y delgadas y el numero de
pares por vuelta difiere.
Cita
bibliográfica.
M. Devlin Thomas. 2000. Bioquímica, libro de texto con aplicaciones
clínicas. Editorial Reverte, S.A. Impreso en México.
http://www.ucm.es/info/genetica/grupod/index.htm
www.korion.com.ar/archivos/biomoleculas.pdf
Biología Molecular y Celular. Lic. Marcelo
F. Goyanes.